
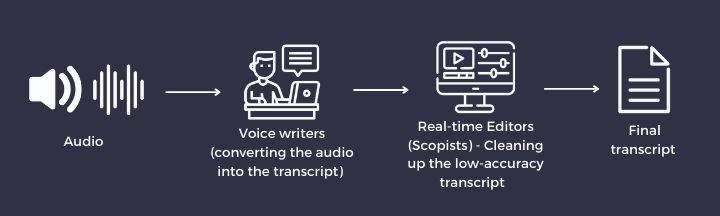
The traditional transcription method - voice writers transcribing through legacy speech-to-text software and scopists (real-time editors) cleaning up the transcript - is a costly and tedious process. But now, ASR (Automatic Speech Recognition) is emerging as a far better alternative as it is cost-effective and convenient and provides high accuracy.
The Need for Audio Transcription
The primary reason behind the adoption of audio transcription was its speed - speech-to-text transcription is 4X faster than manually typing on a keyboard. In some cases, a high documentation speed is required, such as, for court reporting.
A court reporter (also known as a stenographer) needs to capture and document the court proceedings - such as hearings, trials, depositions, discoveries, and testimonies. Here, audio transcription seems a better option than manually typing out the reports.
Another reason is that Voice is a primary mode of communication, and a significant fraction of individuals prefer speaking to typing.

Limitations of the Traditional Transcription Method
In the 1990s, Voice Writing was developed on top of the first-generation speech recognition technology. Although it has played a crucial role in speeding up the transcription process, it has significant limitations, such as user dependency, low accuracy, and expensive software licenses.
The legacy speech recognition platforms were highly sensitive to ambient noise and intonational variation in speech. This means that only a well-trained voice writer can use the software. Typically, even a voice writer trained for 6 months reaches an accuracy of 70 - 80%. This low accuracy is compensated by real-time editors (also known as scopists).

Adopting a New Approach - ASR (Automatic Speech Recognition)
Because of the limitation of the traditional method, transcription professionals started shifting from legacy systems to a more convenient technology - ASR (Automatic Voice Recognition), which enables real-time transcription with high accuracy.
Thanks to rapid advancements in deep learning, ASR (Automatic Speech Recognition) can offer an accuracy of 90%+. The main reason behind this high accuracy is that ASR systems are based on custom models developed for specific environments - language, dialects, accents, nuances, and audio types.
ASR custom models are trained to understand the key language of a particular environment - technical words, brand and product names, and industry-specific jargon. 
Implementation of ASR Models
ASR vendors create custom models using labeled (transcribed) Audio. Based on the audio types and requirements, you can create as many models as you want if you have enough labeled data. There is no cap on the maximum limit - the more labeled data you have, the more efficient your model will be.

Customization is a crucial aspect that impacts the efficiency of a model. Many vendors use the traditional speech recognition infrastructure and add an extra layer of customization at the end. It might give a little better accuracy than the traditional method, but still, the model will be inferior to a fully customized model.
A fully customized model is trained using end-to-end deep learning on the labeled audio data from the beginning. It's like training a child in a language from birth instead of enrolling them in a crash course. 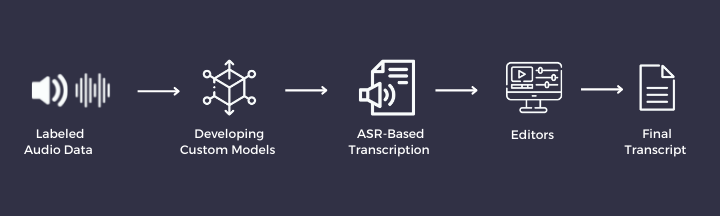
Float NEO – ASR as a Service
Float NEO offers the next-generation ASR technology, helping you build advanced voice applications leveraging Floatbot’s deep tech ASR technology.

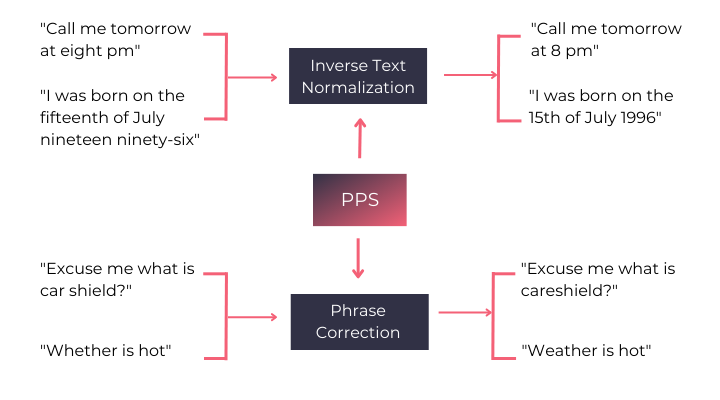
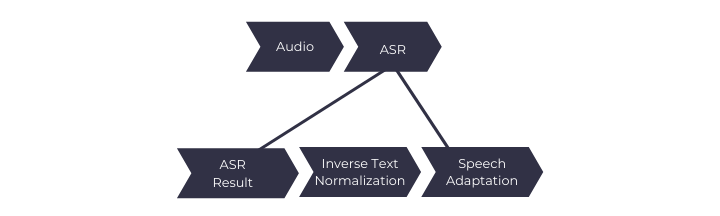
Post Processing Steps
Why Float NEO?
- Accurate speech detection. No spelling mistakes. Proven 99%+ Accuracy
- Real-time transcription, which is 4X faster than manually typing
- Voice biometrics login available for users
- Supported on the cloud as well as the on-premise environment
- Available on Desktop, Mobile app, Web, and Chrome Plugin
- Simple, Easy-to-Use UI. Start transcribing with a single click
- Supports 10+ languages
Conclusion
Traditional speech recognition systems have been around for years but now transcription professionals around the world are ditching them and adopting ASR. The reasons are simple - ASR produces highly accurate transcriptions at lower operational costs. Also, the ASR-based transcription system is convenient, and you don’t need voice writers or special skills to produce transcripts.





