

Large Language Models (LLMs) are a fine reflection of technological advance, and constructing these models is no cakewalk. Companies specializing in LLMs are pouring millions of dollars to train these models, utilizing massive computing infrastructure and a stockpile of data that keeps getting bigger and bigger. However, once trained, LLMs can be endlessly shared, re-shared and even re-purposed. You have probably heard of OpenAI and its extended family of GPT models. However, there is a gold rush for new LLMs and many more models are grabbing eyeballs. Some of them are accessible via an application programming interface (API) while others are open source. In this blog, we shall break down the fine-tuning strategies for domain-specific applications based on LLMs.
Fine Tuning – A Brief Introduction
Fine-tuning a large language model requires adjusting a pre-trained LLM to a specific domain by feeding it task-specific data. This approach leverages the general language understanding (during pre-training) and improves the model for domain-specific applications like sentiment analysis, customer service through conversational agents and much more. However, fine-tuning also comes with its unique challenges where the model "invents'' facts, catastrophic forgetting, etc. Nevertheless, the LLM space is evolving rapidly, and researchers are in a quest to constantly uncover newer strategies to make these models adapt in different domains in a way that offers both value and safety.
The Best Strategies for Domain Specific LLM Fine-Tuning
LLM fine-tuning involves a supervised learning process where one uses a dataset (labeled examples) to improve the weights of LLM and better the model at specific tasks. Let's look at some of the noteworthy fine-tuning strategies.
1. Hyperparameter Tuning
Hyperparameter tuning involves adjusting hyper-parameters such as the epoch, batch size, learning rate, and regularization strength for LLM performance optimization. Meticulous hyperparameter tuning can boost the learning efficiency of the model as it adapts well to new datasets without overfitting.
There are three pivotal hyperparameters to consider:
- Epoch
In easy words, epoch is the number of times a LLM processes an entire dataset. Higher the count of epochs ,the higher is a model's ability to refine its data interpretation. Nevertheless, inflated epochs can sometimes result in overfitting, where the model tends to become overtly specific to the training data while floundering with generalization.
- Learning Rate
The learning rate indicates how fast a LLM updates its parameters when being trained. While a higher learning rate amps up learning, it might risk instability. On the other hand, a lower learning rate ensures stability but stretches the training cycle. There is no one-size-fits-all rate and an optimal learning rate deviates, depending on the LLM application and model architecture.
- Batch Size
Batch size specifies the number of data samples a model processes in one iteration. Bigger batch sizes can boost training but demand more memory. Similarly, smaller batch sizes allow a model to thoroughly process every single record. The preference for batch size must align with the hardware capabilities as well as dataset for optimal results.

2. Addressing Bias Amplification
Humans are biased on the smallest of things! So, it's not surprising that we have passed down this trait to AI. LLMs can demonstrate bias in many ways. It can be a model linking specific jobs with a specific gender or as a model producing offensive content. The bias mirrors the data a model is trained on. Bias amplification can seriously jeopardize the accuracy of LLMs with far-reaching implications.
De-biasing LLMs is not an easy process and involves multiple steps as listed below:
- Pre-processing stage
Prevention is better than cure, right? During the pre-processing stage, it is absolutely important to eliminate (or reduce) the bias sources before feeding them to a LLM. Techniques like data filtering, data balancing, etc are deployed to improve the quality, diversity, and accuracy of data.
- In-processing stage
In this stage, the LLM is optimized to minimize or negate any bias acquired during the LLM learning. Techniques like regularization, fairness constraints, adversarial learning, etc are deployed that discourages an LLM from retaining biased views and generating biased outputs.
- Post-processing stage
LLMs can be further modified during this stage to rectify or compensate for the bias. This involves techniques like output rewriting, output filtering, output ranking, etc, that detects and eliminates bias from the LLM outputs.
- Feedback stage
Human intervention is the ultimate step to monitor and evaluate LLM and moderating the bias response generation, even though it takes time!
3. Tackling Data Scarcity and Domain Mismatch
Imagine trying to depict the vast, complex scenery of a forest with only a few colors. It’s eerily similar with AI modeling, where lack of dataset results can lead to a loss of the richness of insights, resulting in models that are biased, erroneous,and lack generalization. Although we hype about living in the world of Big Data, when it comes to companies trying to apply LLMs for specific applications, they often struggle to stay afloat in a pool of data, which is not quite readily usable for training LLMs. There are many other factors - data sensitivity, copyrights, privacy concerns, and tightening regulatory restrictions that magnifies the problem. For instance, datasets having sensitive information such as medical data or financial records must be handled carefully. One way to tackle this problem is through synthetic data. It is simply a replication of real data that maintains its resemblance while keeping any specific details about real individuals, or entities under wraps. While leveraging synthetic data is innovative and more secure, LLMs often struggle to grasp the complex and nitty-gritties of real-world data, ultimately hampering their performance and utility. Another approach is transfer learning, which refers to the process of leveraging the knowledge acquired by a pre-trained LLM and implementing the same for a specific domain. It involves pre-training where a neural network model gets trained on a large dataset and acquires knowledge. The next phase involves further optimizing the LLM by tweaking the pre-trained model to adapt to specific applications.
4. Retrieval Augmentation Generation
One of the main challenges for modern LLMs is tackling the "Hallucination Problem" which arises when models invent information that looks convincing but is actually fabricated. This happens when the model uses its creativity to fill in the gaps in its knowledge. Retrieval augmented generation (RAG) is a technique that couples information retrieval with natural language generation to make LLM applications adapt to real-world use cases. RAG leverages external up-to-date knowledge sources (relevant documents) to bring the best of both worlds - fact-checked data and human-like fluency. It bridges the void between extensive knowledge of the general-purpose models and the requirement for authentic information with proper context. While conventional fine-tuning While conventional fine-tuning integrates data within the model's architecture (practically 'hard-writing' the knowledge), RAG allows constant updates in training data that paves the way for data removal/revision which ensures that the model stays up-to-date and accurate.
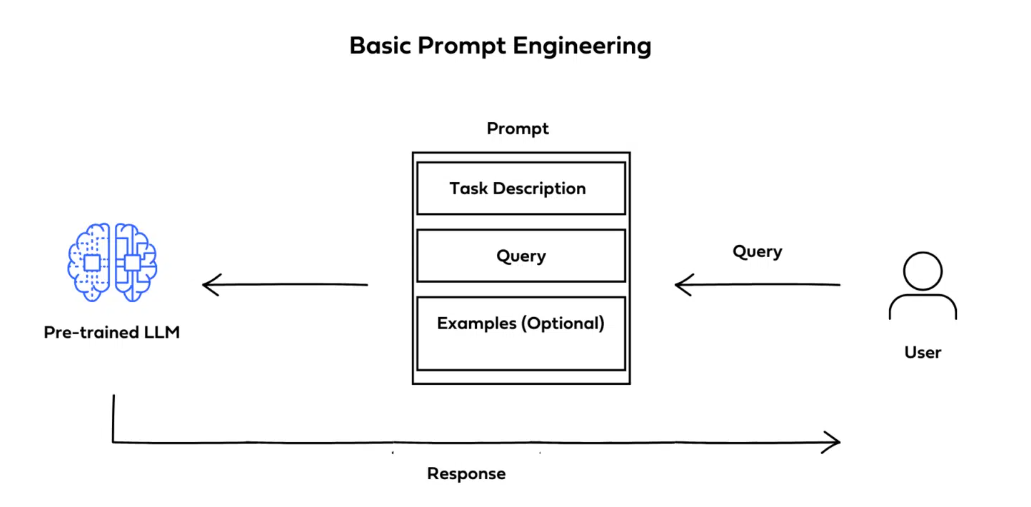
5. Prompt Engineering
We have talked about methods that fine-tune LLMs with hyperparameter tunings, RAGs, etc. Prompt engineering is a very different approach from all of the above since it does not involve training network weights. It involves designing and refining the input provided to a model that ultimately guides and influences the output. For instance, if you wish to produce a creative piece of writing your prompt should ideally be open-ended and inspire originality. On the other hand, if you are hell-bent on retrieving precise factual information, the prompt should be precise and structured. Not only an effective prompt engineering necessitates a grasp of your intent but also involves a deep understanding of language models' interpretation and response to prompts.
Key Aspects of Prompt Engineering
- Task Definition: You must specify an exact task (or question) you want the LLM to execute.
- Prompt or Query: Based on the task, you have to formulate a prompt (or query) for the LLM that pinpoints the task. It serves as an input for the model.
- Inference: The prompt gets processed by the LLM. Subsequently, it generates an output established on the examples provided to it, the task definition, and the prompt.
- Evaluation: Finally, you evaluate the model’s output to determine whether or not the LLM has successfully performed the task.
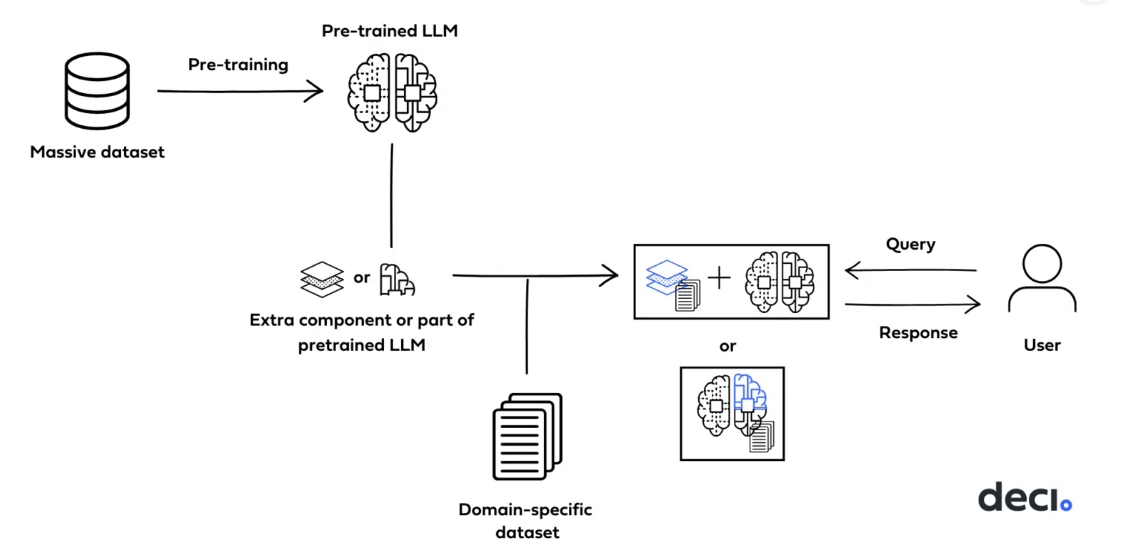
6. Parameter-efficient fine-tuning (PEFT)
PEFT (or Parameter-efficient fine-tuning) is a novel NLP technique that adjusts pre-trained language models seamlessly to diverse applications by fine-tuning just a few parameters, minimizing computational as well as storage costs. It prevents catastrophic forgetting by acclimating key parameters for precise tasks, and delivers similar performance as full fine-tuning across modalities. It's a practical approach to deliver high performance with minimal trainable parameters.
PEFT follows a simplistic two-step process:
- The pre-trained model is coupled with a few adapter layers. These act as a catalyst to adapt the model for new tasks.
- Subsequently, these adapter layers get trained using small packets of data from the new tasks.
Wrapping Up
If you are a brand looking to have virtual agents in the guise of chatbots, you wouldn't want to rely on the LLM alone to ensure the quality of its responses, right? In the multiverse of LLMs, it is important to know the finest fine-tuning techniques- prompt engineering, retrieval augmented generation, etc, to achieve your objectives. These techniques offer versatility for customizing large language models to your specific applications ranging from precise responses or domain expertise. However, the fine-tuning strategies you deploy must match the unique demands of your project. Do you wish to learn more or think about deploying chatbots that seamlessly blend with your business? Contact the Floatbot experts today to discuss more!





